A challenge with predictions for the outbreak is that we only have reported/ known case data for parameter estimation. The first model assumed that all infected cases would ultimately be known cases and that detected cases were equivalent to reported known case data. In our updated model today, detected cases are no longer simply a lag of infected cases but use the fact that a significant portion of infected cases are never reported in known case data.
The fraction that defines this relationship was estimated in recently published analysis of the outbreak in China; using a complex model that included movement between Chinese cities, known cases were estimated to represent only 14% of the total; however they also estimate that the ability to transmit the disease in unknown cases was 55% of that in known cases. It is difficult to see why an unknown case would be less infectious. If we assume that all infectious are equally infectious (on average) whether their case is known or not, this leads to an estimate that about 22% of cases are known based on the China data. We have also taken estimates of the incubation period and infectious period from the China data.
To account for the above treatment of known cases for parameter estimation, the predictive model now includes the following elements:

We have applied the model to both Ireland and Italy today and results are shown below.
 |
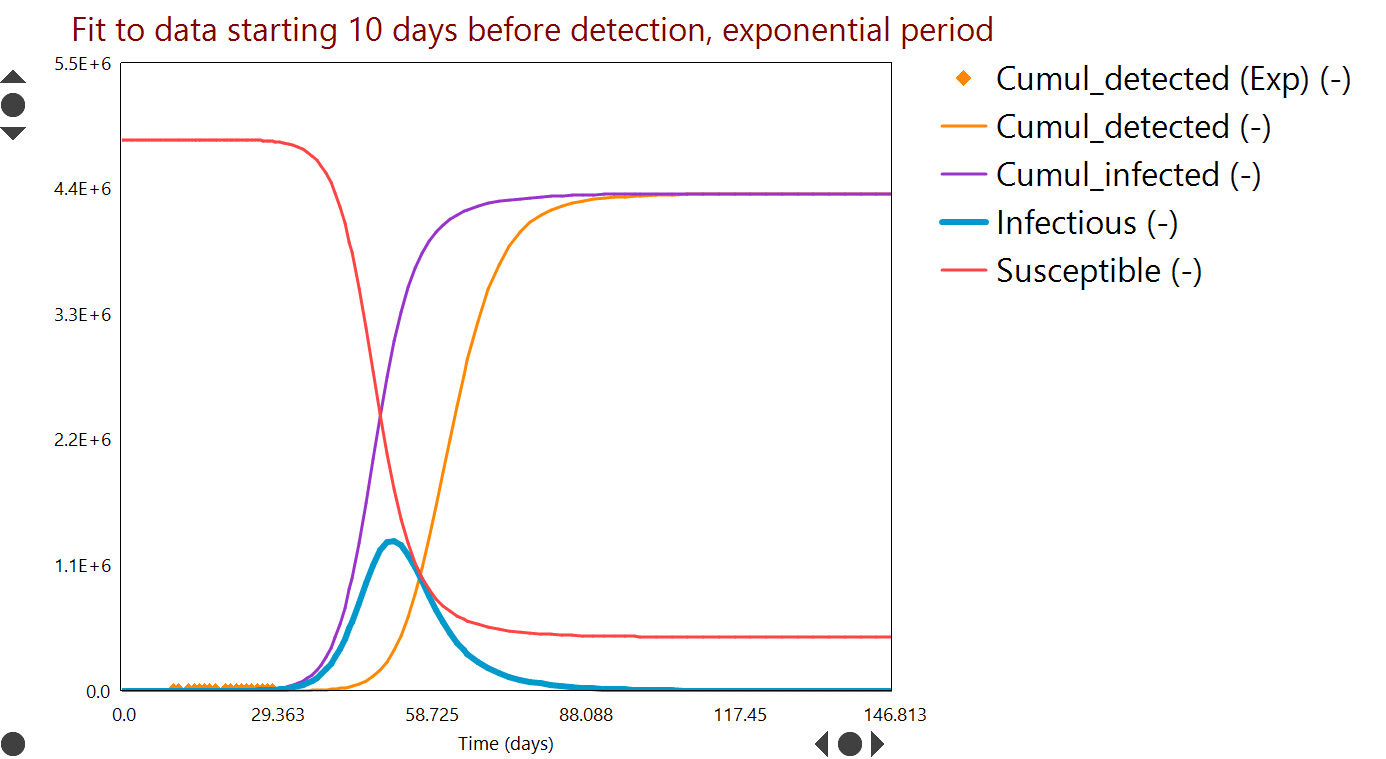
| Model 2 fit for Ireland data, with timeframe to end March 2020 (Day 0 = February 20). Curves are model predictions and symbols are observed data. Plot units are in brackets on the legend. There is a clear indication of how measures have changed the trend in the numbers Exposed and Infectious. |
 |
| Potential impact of on/off restrictions in movement for Ireland to end December 2020. With further limits on people movement [inset], peak ICU needs could be reached in April or June, depending on restrictions. |
 |
| Model fit for Italy data, with timeframe to end March 2020 (Day 0 = February 12). Curves are model predictions and symbols are observed data. Plot units are in brackets on the legend. |
 |
| Potential impact of on/off restrictions in movement for Italy to December 2020. With further limits on people movement [inset], peak ICU needs could be reached around the end of April (day 77 for Italy). Relaxation of restrictions even for a short period could return demand towards peak levels. |
In addition to challenges interpreting known case data, the number of data available are also limited, therefore model parameters are uncertain and predictions are indicative only. In particular, the R0 parameter we obtain by parameter estimation to known case data is 3.0 for Italy and 3.55 for Ireland, both higher than values generally quoted for China. This could reflect differences in social contact patterns, age profile or the importation of cases due to air travel, which are not explicitly included in our model. Both values being higher than China may be an artifact of having too few data at present and makes the current model predict more severe impacts.